在不基于原有特征上人为构造新特征的前提下,线性模型(只有一层的神经网络)很难解决复杂问题,甚至连给简单交叉的点集分类都手足无措. 异或问题 一度成为人工神经网络的梦魇,相关研究停滞了一段时间,直到 20 世纪 70 年代,一种基于 反向传播算法 的神经网络模型很好地解决了这一问题. 此后,对人工神经网络的相关研究迅猛发展.
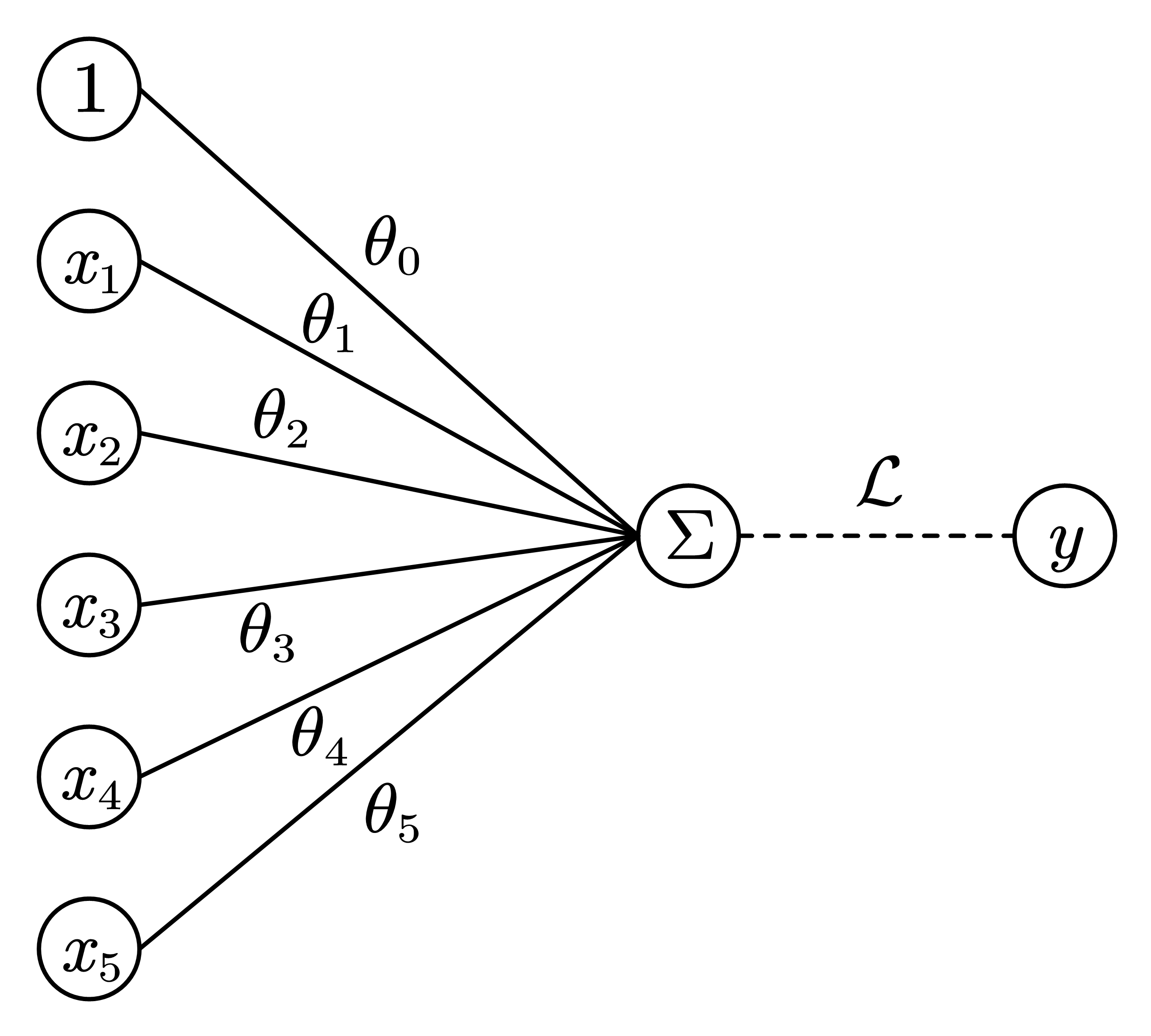
过往的模型 在这之前,我们学习过的线性回归和逻辑回归,都是建立了从样本空间 X \mathcal{X} X Y \mathcal{Y} Y 只有一层 的神经网络:
但一层的局限性很大,如果不引入额外特征加入训练,很难建立复杂的模型,以解决复杂的问题.
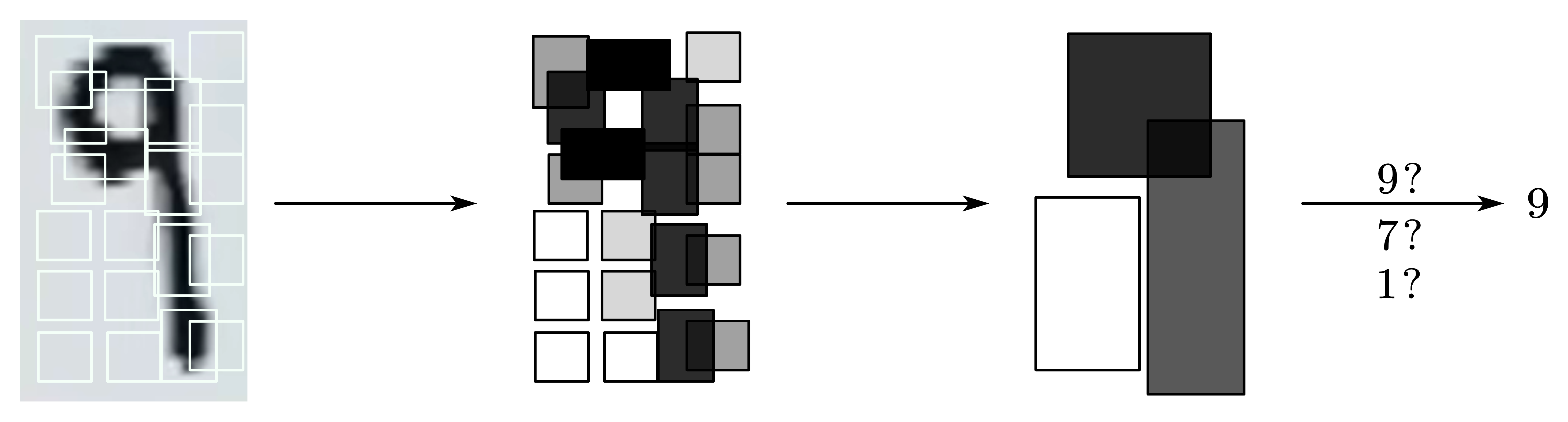
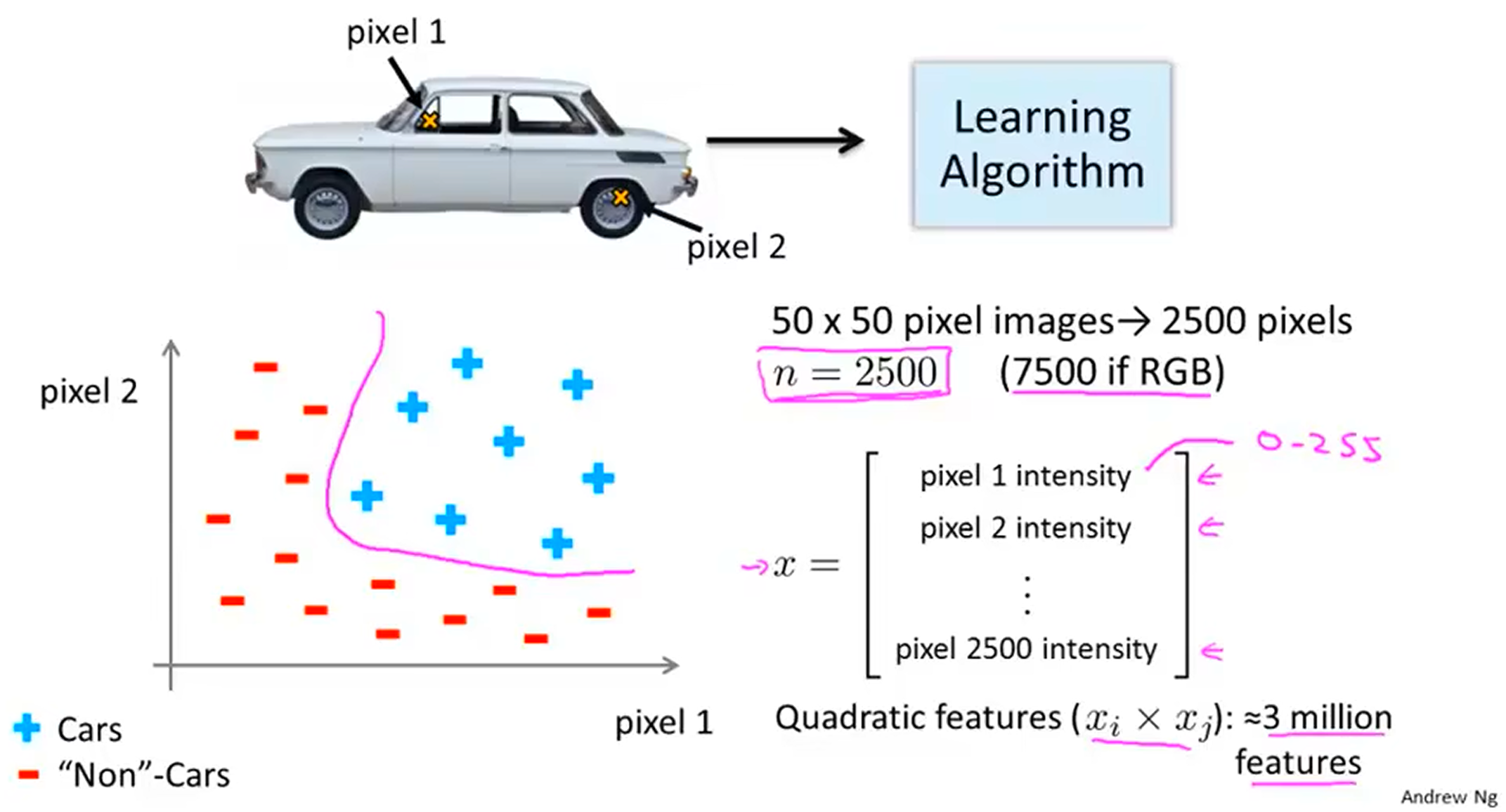
事实上,在计算机视觉(CV)中,样本特征就是图片每个像素点,这导致特征数 O ( n ) O(n) O ( n ) O ( n 2 ) O(n^2) O ( n 2 ) x 1 2 , x 1 x 2 , ⋯ x_{1}^2, x_{1}x_{2}, \cdots x 1 2 , x 1 x 2 , ⋯
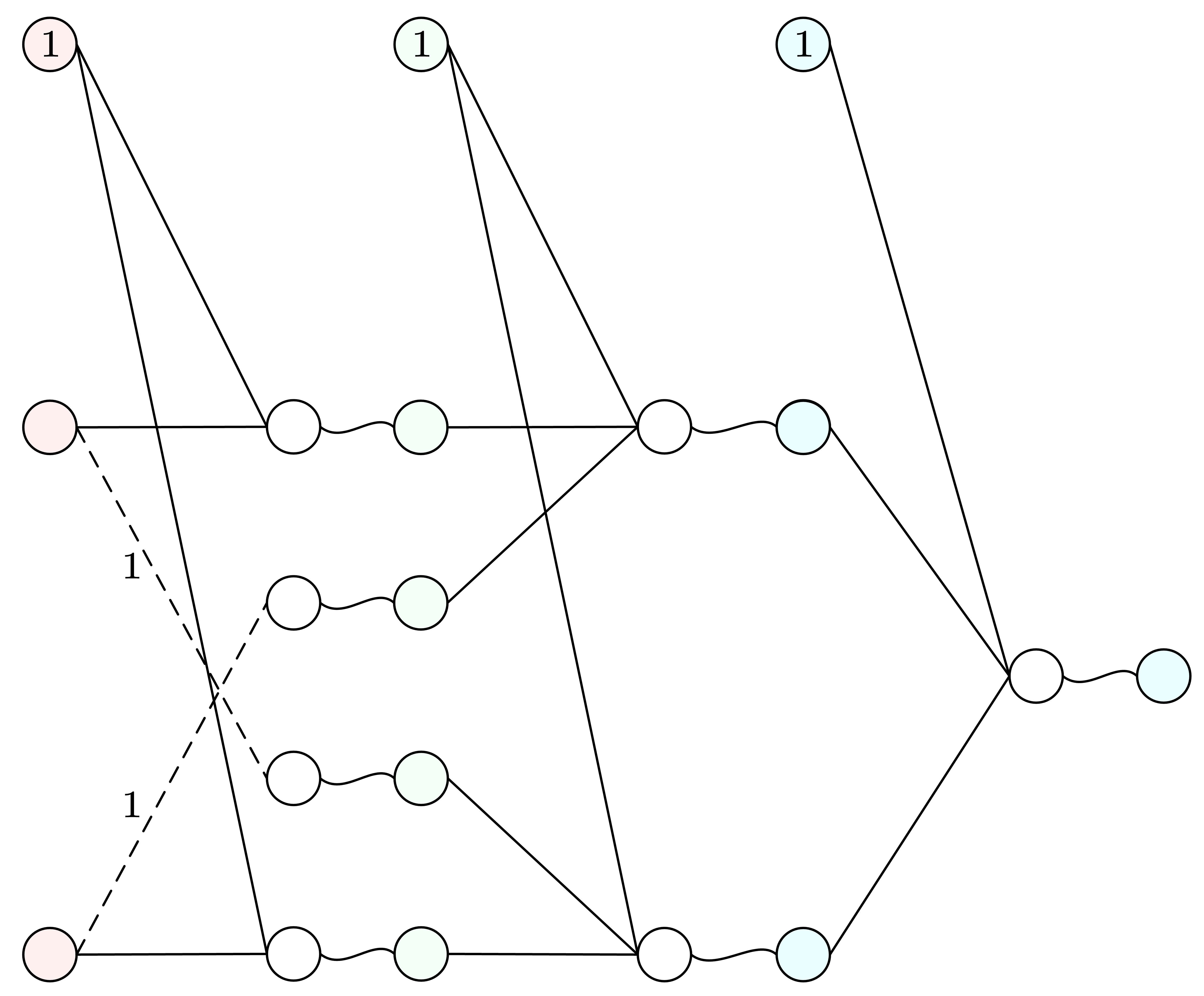
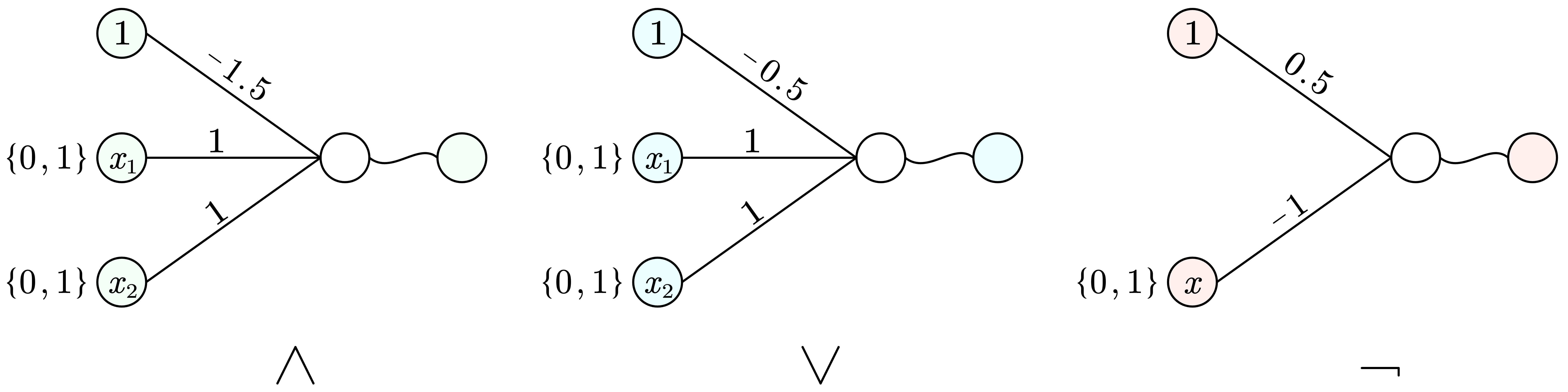
加一层 逻辑电路的设计为我们提供新的思路:如果我们只有与或非 ∧ , ∨ , ¬ \land, \lor, \lnot ∧ , ∨ , ¬ ⊕ \oplus ⊕
(真值表有四行,对应平面上的四个点)可以证明,单凭两种特征对与或非这三种问题是能够进行简单二分类的(线性可分 ):
线性不可分 ),因为你无法使用一条直线将这两类交叉的点群分开来.
事实上 { ∧ , ∨ , ¬ } \{\land, \lor, \lnot\} { ∧ , ∨ , ¬ }
a ⊕ b = ( ¬ a ∧ b ) ∨ ( a ∧ ¬ b ) a \oplus b = (\lnot\, a \land b) \lor (a \land \lnot\, b) a ⊕ b = ( ¬ a ∧ b ) ∨ ( a ∧ ¬ b )
可以看到,在门种类数有限的情况下,门数和门层数的增加是不可避免的.
我们只用了三种门,就能表示所有的逻辑函数.把这个例子搬到机器学习,道理就是:特征种数有限的情况下,“增加层数”能提高模型的复杂度.
“增加层数”在图像识别领域里意味着什么?相比直接把每个像素点值一股脑摆在机器面前,让机器立即判断图片的数字是几,“增加层数”意味着解决不同规模的局部问题,汇总局部结果,解决整体问题.
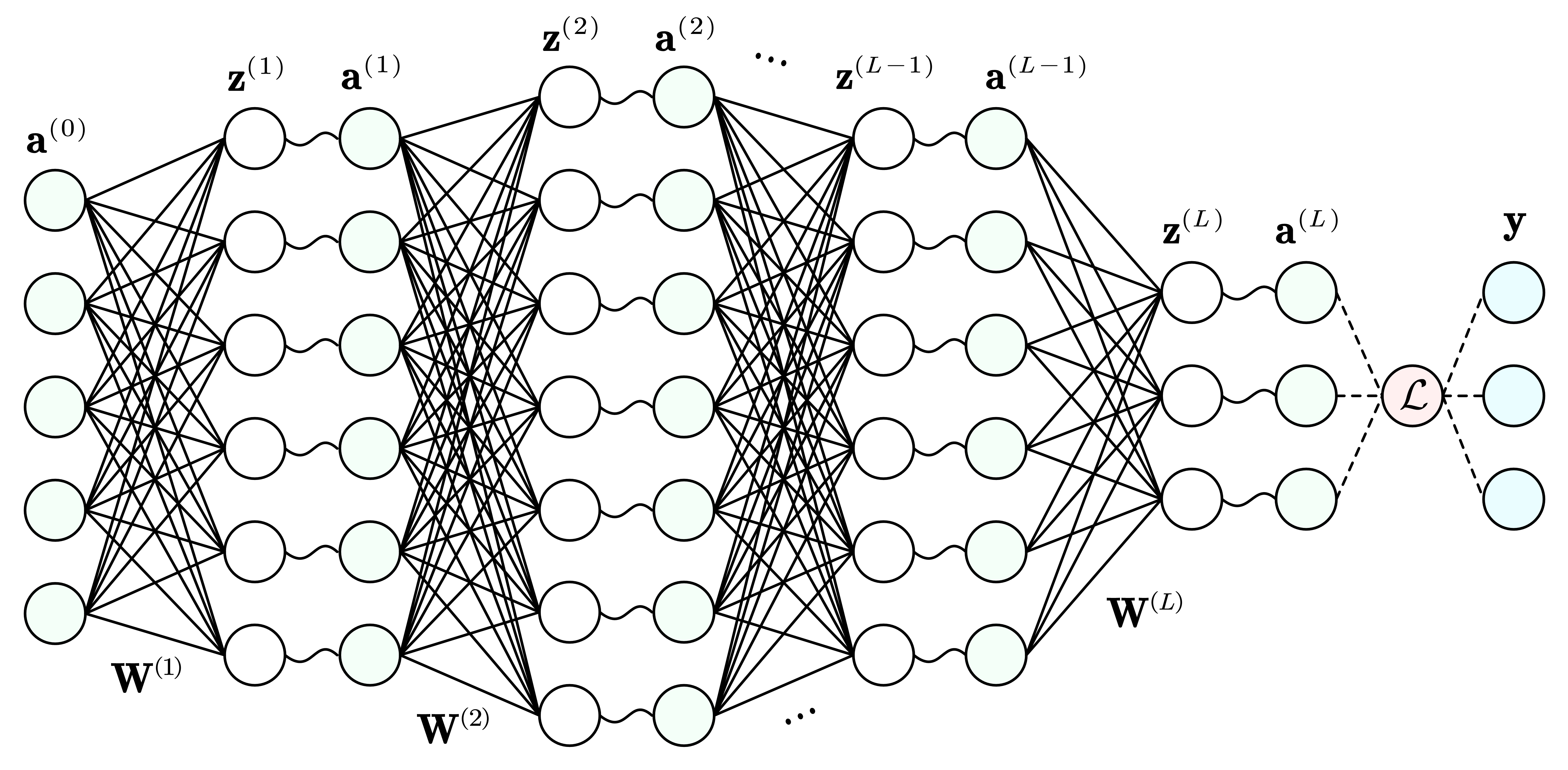
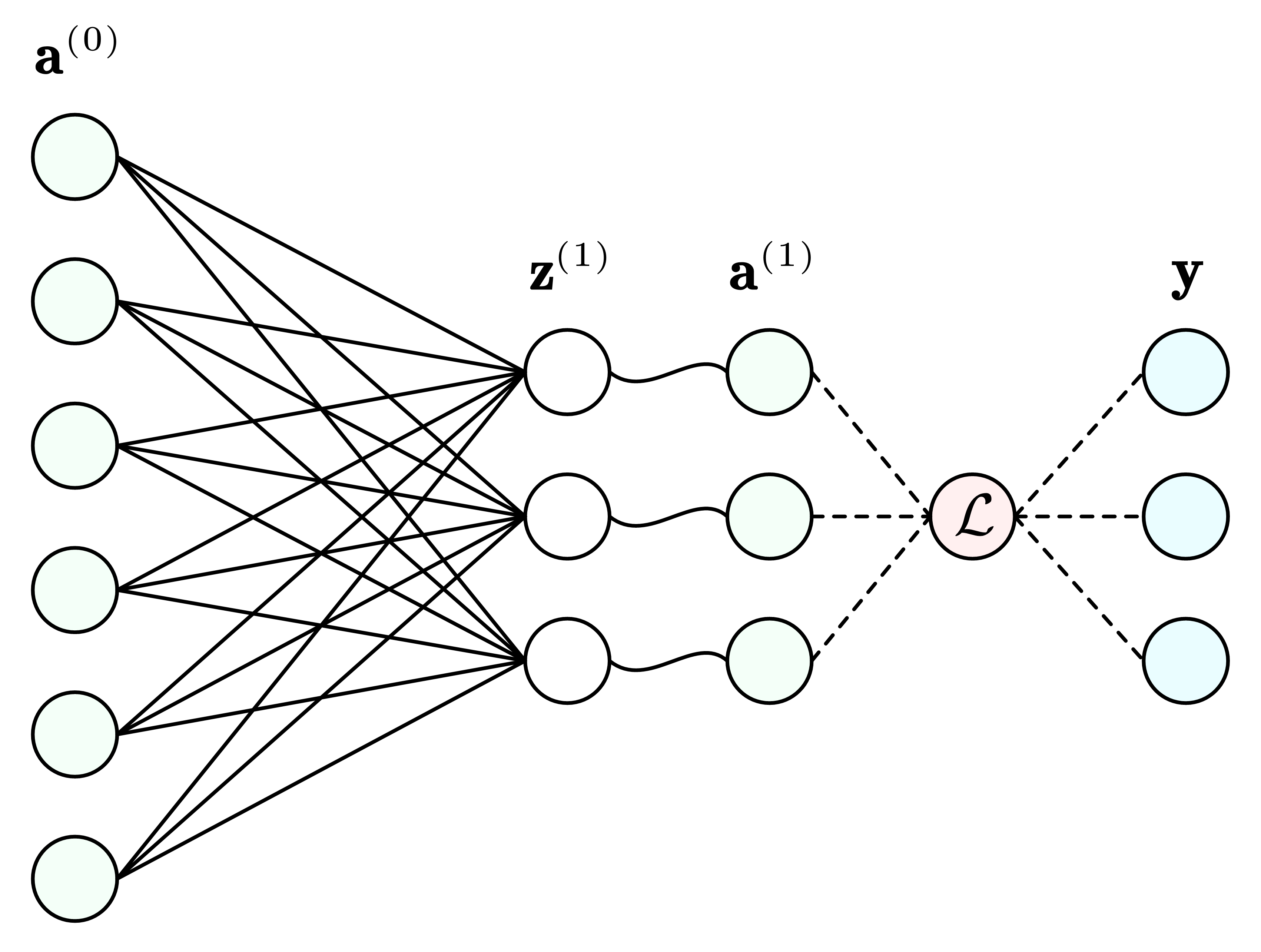
多隐层反馈神经网络 把一层的输出结果再作为输入,我们就得到多层的神经网络(偏置项隐去):
这个神经网络共 ( L + 1 ) (L + 1) ( L + 1 ) 输入层、隐藏层、输出层 .输入层 a ( 0 ) \mathbf{a}^{(0)} a ( 0 ) a ( l − 1 ) \mathbf{a}^{(l - 1)} a ( l − 1 )
z ( l ) = W ( l ) a ( l − 1 ) + b ( l − 1 ) \mathbf{z}^{(l)} = \mathbf{W}^{(l)}\mathbf{a}^{(l - 1)} + \mathbf{b}^{(l - 1)} z ( l ) = W ( l ) a ( l − 1 ) + b ( l − 1 )
线性映射中的每条边权称为 权重 .接着这一层的未激活值会被激活成激活值
a ( l ) = σ ( z ( l ) ) \mathbf{a}^{(l)} = \sigma(\mathbf{z}^{(l)}) a ( l ) = σ ( z ( l ) )
其中 σ ( ⋅ ) \sigma(\cdot) σ ( ⋅ ) 前向传播 .
从输入层 a ( 0 ) \mathbf{a}^{(0)} a ( 0 ) a ( L ) \mathbf{a}^{(L)} a ( L ) 损失函数 的值
L = f ( a ( L ) , y ) \mathcal L = f(\mathbf{a}^{(L)}, \mathbf{y}) L = f ( a ( L ) , y )
在回归任务中,损失函数的值可以是 均方误差(Mean Squared Error, MSE)
L M S E = 1 2 ∥ a ( L ) − y ∥ 2 = 1 2 ∑ i = 1 n L ( a i ( L ) − y i ) 2 \mathcal{L}_\mathrm{MSE}=\frac{1}{2}\|\mathbf{a}^{(L)}-\mathbf{y}\|^2=\frac{1}{2}\sum_{i=1}^{n_L}(a_i^{(L)}-y_i)^2 L MSE = 2 1 ∥ a ( L ) − y ∥ 2 = 2 1 i = 1 ∑ n L ( a i ( L ) − y i ) 2
如果要 正则化 (以 L2 正则化为例,给予高边权值惩罚,防止过拟合),则
L M S E = 1 2 ∥ a ( L ) − y ∥ 2 + λ 2 ∑ l = 1 L ∑ i , j W i j ( l ) 2 = 1 2 ∥ a ( L ) − y ∥ 2 + λ 2 ∑ l = 1 L ∥ W ( l ) ∥ 2 \begin{align*} \mathcal{L}_\mathrm{MSE}&=\frac{1}{2}\|\mathbf{a}^{(L)}-\mathbf{y}\|^2 + \frac{\lambda}{2} \sum_{l = 1}^{L}\sum_{i,j} {W_{ij}^{(l)}}^2 \\ &=\frac{1}{2}\|\mathbf{a}^{(L)}-\mathbf{y}\|^2 + \frac{\lambda}{2} \sum_{l = 1}^{L}\|\mathbf{W}^{(l)}\|^2 \end{align*} L MSE = 2 1 ∥ a ( L ) − y ∥ 2 + 2 λ l = 1 ∑ L i , j ∑ W ij ( l ) 2 = 2 1 ∥ a ( L ) − y ∥ 2 + 2 λ l = 1 ∑ L ∥ W ( l ) ∥ 2
在分类任务中,损失函数的值可以是 交叉熵损失(Cross-Entropy Loss)
L C E = − ∑ i = 1 n L y i log a i ( L ) \mathcal{L}_{\mathrm{CE}}=-\sum_{i=1}^{n_L}y_i\log a_i^{(L)} L CE = − i = 1 ∑ n L y i log a i ( L )
此时激活函数应为 Softmax 函数
a ( L ) = S o f t m a x ( z ( L ) ) \mathbf{a}^{(L)}=\mathrm{Softmax}(\mathbf{z}^{(L)}) a ( L ) = Softmax ( z ( L ) )
即
a i ( L ) = e z i ( L ) e z 1 ( L ) + e z 2 ( L ) + ⋯ + e z n L ( L ) a_i^{(L)}=\frac{e^{z_i^{(L)}}}{e^{z_1^{(L)}} + e^{z_2^{(L)}} + \cdots + e^{z_{n_{L}}^{(L)}}} a i ( L ) = e z 1 ( L ) + e z 2 ( L ) + ⋯ + e z n L ( L ) e z i ( L )
反向传播算法 为了最小化损失函数的值,我们沿用 梯度下降 的方法:找到损失函数 L \mathcal L L W i j ( l ) W_{ij}^{(l)} W ij ( l ) ∂ L ∂ W \frac{\partial \mathcal L}{\partial W} ∂ W ∂ L
在之前只有一层的神经网络中,我们能够根据当前输出值 X θ X\theta Xθ y y y X X X
∇ θ J = 1 m X T ( X θ − y ) \nabla_{\theta}\,J = \frac{1}{m}X^\text{T}(X\theta - y) ∇ θ J = m 1 X T ( Xθ − y )
这种处理意味着单层结构中,损失函数关于参数偏导数的求法我们能一步到位,但现在有多层结构,我们要求中间损失函数关于某一层某一条连接的边权的偏导数 ∂ L ∂ W i j ( l ) \frac{\partial \mathcal L}{\partial W_{ij}^{(l)}} ∂ W ij ( l ) ∂ L
联想到我们在求多元复合函数偏导数的时候,会画出函数的复合结构图,找出从某一自变量出发,到达目标因变量的所有路径,进而根据 链式法则 写出偏导表达式.前向传播的过程正是函数复合的过程,这个函数的复合结构图就是我们的神经网络图.
之前我们实现了只有一层的,从输出值和标签值出发的偏导数求法.
对于多层,从目标边权 W i j ( l ) W_{ij}^{(l)} W ij ( l ) a ( L ) \mathbf{a}^{(L)} a ( L ) L \mathcal L L a ( L ) \mathbf{a}^{(L)} a ( L )
我们从输出层 L L L L \mathcal L L L L L a ( L ) \mathbf{a}^{(L)} a ( L ) ∂ L ∂ a ( L ) \frac{\partial \mathcal L}{\partial \mathbf{a}^{(L)}} ∂ a ( L ) ∂ L L L L z ( L ) \mathbf{z}^{(L)} z ( L ) L L L a ( L ) \mathbf{a}^{(L)} a ( L ) z ( L ) \mathbf{z}^{(L)} z ( L ) ∂ a ( L ) ∂ z ( L ) \frac{\partial \mathbf{a}^{(L)}}{\partial \mathbf{z}^{(L)}} ∂ z ( L ) ∂ a ( L )
δ ( L ) = ∂ L ∂ z ( L ) = ( ∂ a ( L ) ∂ z ( L ) ) ⊤ ∂ L ∂ a ( L ) = [ ( diag σ ′ ) ( z ( L ) ) ] ∂ L ∂ a ( L ) = ∂ L ∂ a ( L ) ⊙ σ ′ ( z ( L ) ) \boldsymbol\delta^{(L)} = \frac{\partial \mathcal L}{\partial \mathbf{z}^{(L)}} = \left( \frac{\partial \mathbf{a}^{(L)}}{\partial \mathbf{z}^{(L)}} \right)^\top \frac{\partial \mathcal L}{\partial \mathbf{a}^{(L)}} = [(\text{diag} \,\sigma')(\mathbf{z}^{(L)})] \frac{\partial \mathcal L}{\partial \mathbf{a}^{(L)}} = \frac{\partial \mathcal L}{\partial \mathbf{a}^{(L)}} \odot \sigma'(\mathbf{z}^{(L)}) δ ( L ) = ∂ z ( L ) ∂ L = ( ∂ z ( L ) ∂ a ( L ) ) ⊤ ∂ a ( L ) ∂ L = [( diag σ ′ ) ( z ( L ) )] ∂ a ( L ) ∂ L = ∂ a ( L ) ∂ L ⊙ σ ′ ( z ( L ) )
(对应元素操作的雅可比矩阵为对角阵,对角阵与向量的相乘退化成两个向量逐元素相乘 ⊙ \odot ⊙ L L L 误差项 ,这样我们就把第一步给完成了:输出层的误差计算 .
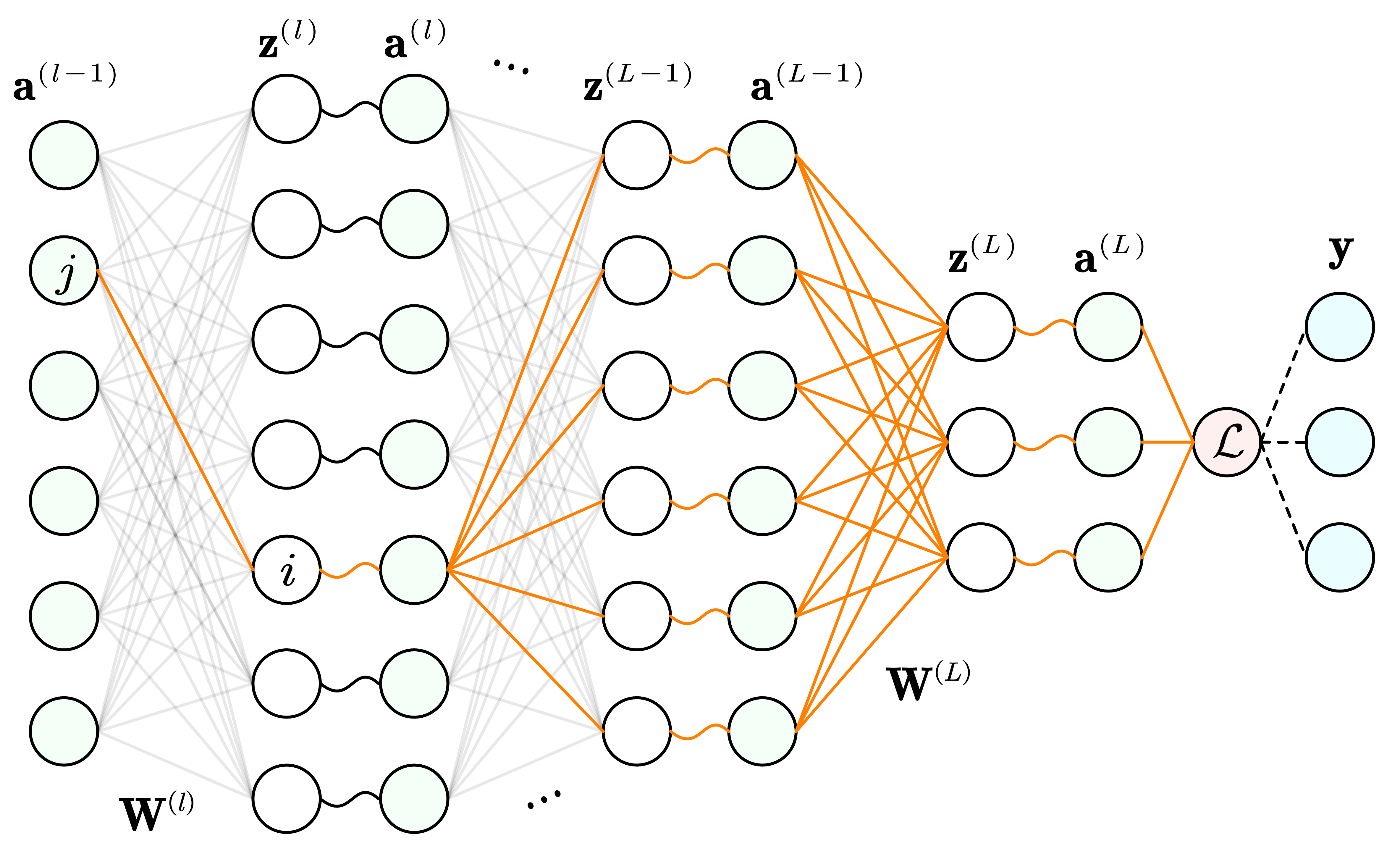
中间隔了那么多的隐藏层怎么传到目标边权 W i j ( l ) W_{ij}^{(l)} W ij ( l ) 隐藏层之间的误差项的传递 :考虑从第 ( l + 1 ) (l + 1) ( l + 1 ) δ ( l + 1 ) \boldsymbol\delta^{(l + 1)} δ ( l + 1 ) l l l δ ( l ) \boldsymbol\delta^{(l)} δ ( l )
z ( l + 1 ) = W ( l + 1 ) a ( l ) + b ( l ) a ( l ) = σ ( z ( l ) ) \begin{align*} \mathbf{z}^{(l + 1)} &= \mathbf{W}^{(l + 1)}\mathbf{a}^{(l)} + \mathbf{b}^{(l)} \\ \mathbf{a}^{(l)} &= \sigma(\mathbf{z}^{(l)})\end{align*} z ( l + 1 ) a ( l ) = W ( l + 1 ) a ( l ) + b ( l ) = σ ( z ( l ) )
因此
δ ( l ) = ∂ L ∂ z ( l ) = ( ∂ z ( l + 1 ) ∂ z ( l ) ) ⊤ ∂ L ∂ z ( l + 1 ) = ( ∂ z ( l + 1 ) ∂ a ( l ) ∂ a ( l ) ∂ z ( l ) ) ⊤ ∂ L ∂ z ( l + 1 ) = ( W ( l + 1 ) [ ( diag σ ′ ) ( z ( l ) ) ] ) ⊤ δ ( l + 1 ) = [ ( diag σ ′ ) ( z ( l ) ) ] ⊤ ( W ( l + 1 ) ⊤ δ ( l + 1 ) ) = ( W ( l + 1 ) ⊤ δ ( l + 1 ) ) ⊙ σ ′ ( z ( l ) ) \begin{align*}\boldsymbol\delta^{(l)} &= \frac{\partial \mathcal L}{\partial \mathbf{z}^{(l)}} = \left( \frac{\partial \mathbf{z}^{(l + 1)}}{\partial \mathbf{z}^{(l)}} \right)^\top \frac{\partial \mathcal L}{\partial \mathbf{z}^{(l + 1)}} = \left( \frac{\partial \mathbf{z}^{(l + 1)}}{\partial \mathbf{a}^{(l)}} \frac{\partial \mathbf{a}^{(l)}}{\partial \mathbf{z}^{(l)}} \right)^\top \frac{\partial \mathcal L}{\partial \mathbf{z}^{(l + 1)}} \\ &= (\mathbf{W}^{(l + 1)} [(\text{diag} \,\sigma')(\mathbf{z}^{(l)})])^\top \boldsymbol\delta^{(l + 1)} = [(\text{diag} \,\sigma')(\mathbf{z}^{(l)})]^\top ({\mathbf{W}^{(l + 1)}}^\top \boldsymbol\delta^{(l + 1)}) \\ &= ({\mathbf{W}^{(l + 1)}}^\top \boldsymbol\delta^{(l + 1)}) \odot \sigma'(\mathbf{z}^{(l)})\end{align*} δ ( l ) = ∂ z ( l ) ∂ L = ( ∂ z ( l ) ∂ z ( l + 1 ) ) ⊤ ∂ z ( l + 1 ) ∂ L = ( ∂ a ( l ) ∂ z ( l + 1 ) ∂ z ( l ) ∂ a ( l ) ) ⊤ ∂ z ( l + 1 ) ∂ L = ( W ( l + 1 ) [( diag σ ′ ) ( z ( l ) )] ) ⊤ δ ( l + 1 ) = [( diag σ ′ ) ( z ( l ) ) ] ⊤ ( W ( l + 1 ) ⊤ δ ( l + 1 ) ) = ( W ( l + 1 ) ⊤ δ ( l + 1 ) ) ⊙ σ ′ ( z ( l ) )
一直往回传,误差项传到第 l l l 参数偏导数计算 .
由于目标边权 W i j ( l ) W_{ij}^{(l)} W ij ( l ) z i ( l ) z_{i}^{(l)} z i ( l )
z i ( l ) = ∑ j = 1 n l W i j ( l ) a j ( l − 1 ) + b i ( l ) z_{i}^{(l)} = \sum_{j=1}^{n_{l}} W_{ij}^{(l)}a_{j}^{(l - 1)} + b_{i}^{(l)} z i ( l ) = j = 1 ∑ n l W ij ( l ) a j ( l − 1 ) + b i ( l )
因此
∂ L ∂ W i j ( l ) = ( ∂ z ( l ) ∂ W i j ( l ) ) ⊤ ∂ L ∂ z ( l ) = δ i ( l ) a j ( l − 1 ) \frac{\partial \mathcal L}{\partial W_{ij}^{(l)}} = \left( \frac{\partial \mathbf{z}^{(l)}}{\partial W_{ij}^{(l)}} \right)^\top \frac{\partial \mathcal L}{\partial \mathbf{z}^{(l)}} = \delta_{i}^{(l)}a_{j}^{(l - 1)} ∂ W ij ( l ) ∂ L = ( ∂ W ij ( l ) ∂ z ( l ) ) ⊤ ∂ z ( l ) ∂ L = δ i ( l ) a j ( l − 1 )
更一般地,损失函数 L \mathcal L L l l l W ( l ) \mathbf{W}^{(l)} W ( l )
∂ L ∂ W ( l ) = δ ( l ) a ( l − 1 ) ⊤ \frac{\partial \mathcal L}{\partial \mathbf{W}^{(l)}} = \boldsymbol\delta^{(l)}{\mathbf{a}^{(l - 1)}}^\top ∂ W ( l ) ∂ L = δ ( l ) a ( l − 1 ) ⊤
损失函数 L \mathcal L L l l l b ( l ) \mathbf{b}^{(l)} b ( l )
∂ L ∂ b ( l ) = ( ∂ z ( l ) ∂ b ( l ) ) ⊤ ∂ L ∂ z ( l ) = I ⊤ δ ( l ) = δ ( l ) \frac{\partial \mathcal L}{\partial \mathbf{b}^{(l)}} = \left( \frac{\partial \mathbf{z}^{(l)}}{\partial \mathbf{b}^{(l)}} \right)^\top \frac{\partial \mathcal L}{\partial \mathbf{z}^{(l)}} = I^\top \boldsymbol\delta^{(l)} = \boldsymbol\delta^{(l)} ∂ b ( l ) ∂ L = ( ∂ b ( l ) ∂ z ( l ) ) ⊤ ∂ z ( l ) ∂ L = I ⊤ δ ( l ) = δ ( l )
如果实施 L2 正则化,则修正梯度
∂ L ∂ W ( l ) = δ ( l ) a ( l − 1 ) ⊤ + λ W ( l ) \frac{\partial \mathcal L}{\partial \mathbf{W}^{(l)}} = \boldsymbol\delta^{(l)}{\mathbf{a}^{(l - 1)}}^\top + \lambda \mathbf{W}^{(l)} ∂ W ( l ) ∂ L = δ ( l ) a ( l − 1 ) ⊤ + λ W ( l )
总的来看,
δ ( L ) = ∂ L ∂ a ( L ) ⊙ σ ′ ( z ( L ) ) δ ( L − 1 ) = ( W ( L ) ⊤ δ ( L ) ) ⊙ σ ′ ( z ( L − 1 ) ) ⋮ δ ( l + 1 ) = ( W ( l + 2 ) ⊤ δ ( l + 2 ) ) ⊙ σ ′ ( z ( l + 1 ) ) δ ( l ) = ( W ( l + 1 ) ⊤ δ ( l + 1 ) ) ⊙ σ ′ ( z ( l ) ) ∂ L ∂ W ( l ) = δ ( l ) a ( l − 1 ) ⊤ \begin{align*} \boldsymbol\delta^{(L)} &= \frac{\partial \mathcal L}{\partial \mathbf{a}^{(L)}} \odot \sigma'(\mathbf{z}^{(L)}) \\ \boldsymbol\delta^{(L - 1)} &= ({\mathbf{W}^{(L)}}^\top \boldsymbol\delta^{(L)}) \odot \sigma'(\mathbf{z}^{(L - 1)}) \\ &\:\,\,\vdots \\ \boldsymbol\delta^{(l + 1)} &= ({\mathbf{W}^{(l + 2)}}^\top \boldsymbol\delta^{(l + 2)}) \odot \sigma'(\mathbf{z}^{(l + 1)}) \\ \boldsymbol\delta^{(l)} &=({\mathbf{W}^{(l + 1)}}^\top \boldsymbol\delta^{(l + 1)}) \odot \sigma'(\mathbf{z}^{(l)}) \\ \frac{\partial \mathcal L}{\partial \mathbf{W}^{(l)}} &= \boldsymbol\delta^{(l)}{\mathbf{a}^{(l - 1)}}^\top\end{align*} δ ( L ) δ ( L − 1 ) δ ( l + 1 ) δ ( l ) ∂ W ( l ) ∂ L = ∂ a ( L ) ∂ L ⊙ σ ′ ( z ( L ) ) = ( W ( L ) ⊤ δ ( L ) ) ⊙ σ ′ ( z ( L − 1 ) ) ⋮ = ( W ( l + 2 ) ⊤ δ ( l + 2 ) ) ⊙ σ ′ ( z ( l + 1 ) ) = ( W ( l + 1 ) ⊤ δ ( l + 1 ) ) ⊙ σ ′ ( z ( l ) ) = δ ( l ) a ( l − 1 ) ⊤
这个误差项往回传的过程我们称为 反向传播(BP, Back Propagation) .
对于 MSE + Sigmoid ,
∂ L ∂ a ( L ) = ∂ ∂ a ( L ) 1 2 ∥ a ( L ) − y ∥ 2 = I ⊤ ( a ( L ) − y ) = a ( L ) − y \frac{\partial \mathcal L}{\partial \mathbf{a}^{(L)}} = \frac{\partial}{\partial \mathbf{a}^{(L)}}\frac{1}{2}\|\mathbf{a}^{(L)}-\mathbf{y}\|^2 = I^\top (\mathbf{a}^{(L)}-\mathbf{y}) = \mathbf{a}^{(L)}-\mathbf{y} ∂ a ( L ) ∂ L = ∂ a ( L ) ∂ 2 1 ∥ a ( L ) − y ∥ 2 = I ⊤ ( a ( L ) − y ) = a ( L ) − y
且
σ ′ ( ⋅ ) = σ ( ⋅ ) ( 1 − σ ( ⋅ ) ) \sigma'(\cdot) = \sigma(\cdot)(1-\sigma(\cdot)) σ ′ ( ⋅ ) = σ ( ⋅ ) ( 1 − σ ( ⋅ ))
批量训练 因此,对于含 m m m { ( a ( 0 ) , y ) } \{(\mathbf{a}^{(0)}, \mathbf{y})\} {( a ( 0 ) , y )}
初始化网络边权 W ( l ) ← O \mathbf{W}^{(l)} \gets \mathbf{O} W ( l ) ← O b ( l ) ← 0 \mathbf{b}^{(l)} \gets \mathbf{0} b ( l ) ← 0 每次迭代:初始化 L ← 0 \mathcal L \gets 0 L ← 0 ( a ( 0 ) , y ) (\mathbf{a}^{(0)}, \mathbf{y}) ( a ( 0 ) , y ) 前向传播:z ( l ) ← W ( l ) a ( l − 1 ) + b ( l ) \mathbf{z}^{(l)} \gets \mathbf{W}^{(l)}\mathbf{a}^{(l - 1)} + \mathbf{b}^{(l)} z ( l ) ← W ( l ) a ( l − 1 ) + b ( l ) a ( l ) ← σ ( z ( l ) ) \mathbf{a}^{(l)} \gets \sigma(\mathbf{z}^{(l)}) a ( l ) ← σ ( z ( l ) ) 累计损失函数:L ← L + 1 2 m ∥ a ( L ) − y ∥ 2 \mathcal L \gets \mathcal L + \frac{1}{2m} \|\mathbf{a}^{(L)} - \mathbf{y}\|^2 L ← L + 2 m 1 ∥ a ( L ) − y ∥ 2 添加正则项:L ← L + λ 2 ∑ l ∥ W ( l ) ∥ 2 \mathcal L \gets \mathcal L + \frac{\lambda}{2} \sum_{l} {\|\mathbf{W}^{(l)}\|}^2 L ← L + 2 λ ∑ l ∥ W ( l ) ∥ 2 反向传播:输出层误差:δ ( L ) ← ∂ L ∂ a ( L ) ⊙ σ ′ ( z ( L ) ) \boldsymbol\delta^{(L)} \gets \frac{\partial \mathcal L}{\partial \mathbf{a}^{(L)}} \odot \sigma'(\mathbf{z}^{(L)}) δ ( L ) ← ∂ a ( L ) ∂ L ⊙ σ ′ ( z ( L ) ) 隐层传播到第一层:初始化 ∂ L ∂ W ( l ) ← O \frac{\partial \mathcal L}{\partial \mathbf{W}^{(l)}} \gets \mathbf{O} ∂ W ( l ) ∂ L ← O ∂ L ∂ b ( l ) ← 0 \frac{\partial \mathcal L}{\partial \mathbf{b}^{(l)}} \gets \mathbf{0} ∂ b ( l ) ∂ L ← 0 l l l 误差:δ ( l ) ← ( W ( l + 1 ) ⊤ δ ( l + 1 ) ) ⊙ σ ′ ( z ( l ) ) \boldsymbol\delta^{(l)} \gets ({\mathbf{W}^{(l + 1)}}^\top \boldsymbol\delta^{(l + 1)}) \odot \sigma'(\mathbf{z}^{(l)}) δ ( l ) ← ( W ( l + 1 ) ⊤ δ ( l + 1 ) ) ⊙ σ ′ ( z ( l ) ) 梯度累计:∂ L ∂ W ( l ) ← ∂ L ∂ W ( l ) + 1 m δ ( l ) a ( l − 1 ) ⊤ \frac{\partial \mathcal L}{\partial \mathbf{W}^{(l)}} \gets \frac{\partial \mathcal L}{\partial \mathbf{W}^{(l)}} + \frac{1}{m}\boldsymbol\delta^{(l)}{\mathbf{a}^{(l - 1)}}^\top ∂ W ( l ) ∂ L ← ∂ W ( l ) ∂ L + m 1 δ ( l ) a ( l − 1 ) ⊤ ∂ L ∂ b ( l ) ← ∂ L ∂ b ( l ) + 1 m δ ( l ) \frac{\partial \mathcal L}{\partial \mathbf{b}^{(l)}} \gets \frac{\partial \mathcal L}{\partial \mathbf{b}^{(l)}} + \frac{1}{m}\boldsymbol\delta^{(l)} ∂ b ( l ) ∂ L ← ∂ b ( l ) ∂ L + m 1 δ ( l ) 添加正则项:∂ L ∂ W ( l ) ← ∂ L ∂ W ( l ) + λ W ( l ) \frac{\partial \mathcal L}{\partial \mathbf{W}^{(l)}} \gets \frac{\partial \mathcal L}{\partial \mathbf{W}^{(l)}} + \lambda \mathbf{W}^{(l)} ∂ W ( l ) ∂ L ← ∂ W ( l ) ∂ L + λ W ( l ) 更新:W ( l ) ← W ( l ) − α ∂ L ∂ W ( l ) \mathbf{W}^{(l)} \gets \mathbf{W}^{(l)} - \alpha \frac{\partial \mathcal L}{\partial \mathbf{W}^{(l)}} W ( l ) ← W ( l ) − α ∂ W ( l ) ∂ L b ( l ) ← b ( l ) − α ∂ L ∂ b ( l ) \mathbf{b}^{(l)} \gets \mathbf{b}^{(l)} - \alpha \frac{\partial \mathcal L}{\partial \mathbf{b}^{(l)}} b ( l ) ← b ( l ) − α ∂ b ( l ) ∂ L 我们也可以不显式遍历样本,把训练集里的所有样本合并成矩阵 A ( 0 ) \mathbf{A}^{(0)} A ( 0 ) Y \mathbf{Y} Y A ( 0 ) ∈ R n 0 × m \mathbf{A}^{(0)} \in \mathbb{R}^{n_{0} \times m} A ( 0 ) ∈ R n 0 × m Y ∈ R n L × m \mathbf{Y} \in \mathbb{R}^{n_{L} \times m} Y ∈ R n L × m A \mathbf{A} A
初始化网络边权 W ( l ) ← O \mathbf{W}^{(l)} \gets \mathbf{O} W ( l ) ← O b ( l ) ← 0 \mathbf{b}^{(l)} \gets \mathbf{0} b ( l ) ← 0 每次迭代:前向传播:Z ( l ) = W ( l ) A ( l − 1 ) + b ( l ) \mathbf{Z}^{(l)} = \mathbf{W}^{(l)}\mathbf{A}^{(l - 1)} + \mathbf{b}^{(l)} Z ( l ) = W ( l ) A ( l − 1 ) + b ( l ) A ( l ) = σ ( Z ( l ) ) \mathbf{A}^{(l)} = \sigma(\mathbf{Z}^{(l)}) A ( l ) = σ ( Z ( l ) ) b ( l ) \mathbf{b}^{(l)} b ( l ) B ( l ) ∈ R n l × m \mathbf{B}^{(l)} \in \mathbb{R}^{n_{l} \times m} B ( l ) ∈ R n l × m 损失函数:L ← 1 2 m ∥ A ( L ) − Y ∥ 2 + λ 2 ∑ l ∥ W ( l ) ∥ 2 \mathcal L \gets \frac{1}{2m} \|\mathbf{A}^{(L)} - \mathbf{Y}\|^2 + \frac{\lambda}{2} \sum_{l} {\|\mathbf{W}^{(l)}\|}^2 L ← 2 m 1 ∥ A ( L ) − Y ∥ 2 + 2 λ ∑ l ∥ W ( l ) ∥ 2 反向传播:输出层误差:Δ ( L ) ← ∂ L ∂ A ( L ) ⊙ σ ′ ( Z ( L ) ) \boldsymbol\Delta^{(L)} \gets \frac{\partial \mathcal L}{\partial \mathbf{A}^{(L)}} \odot \sigma'(\mathbf{Z}^{(L)}) Δ ( L ) ← ∂ A ( L ) ∂ L ⊙ σ ′ ( Z ( L ) ) 隐层传播到第一层:到第 l l l 误差:Δ ( l ) ← ( W ( l + 1 ) ⊤ Δ ( l + 1 ) ) ⊙ σ ′ ( Z ( l ) ) \boldsymbol\Delta^{(l)} \gets ({\mathbf{W}^{(l + 1)}}^\top \boldsymbol\Delta^{(l + 1)}) \odot \sigma'(\mathbf{Z}^{(l)}) Δ ( l ) ← ( W ( l + 1 ) ⊤ Δ ( l + 1 ) ) ⊙ σ ′ ( Z ( l ) ) 梯度:∂ L ∂ W ( l ) = 1 m Δ ( l ) A ( l − 1 ) ⊤ + λ W ( l ) \frac{\partial \mathcal L}{\partial \mathbf{W}^{(l)}} = \frac{1}{m}\boldsymbol\Delta^{(l)}{\mathbf{A}^{(l - 1)}}^\top + \lambda\mathbf{W}^{(l)} ∂ W ( l ) ∂ L = m 1 Δ ( l ) A ( l − 1 ) ⊤ + λ W ( l ) ∂ L ∂ b ( l ) = 1 m Δ ( l ) 1 m \frac{\partial \mathcal L}{\partial \mathbf{b}^{(l)}} = \frac{1}{m}\mathbf{\Delta}^{(l)}\mathbf{1}_{m} ∂ b ( l ) ∂ L = m 1 Δ ( l ) 1 m 1 m \mathbf{1}_{m} 1 m Δ ( l ) \mathbf{\Delta}^{(l)} Δ ( l ) 更新:W ( l ) ← W ( l ) − α ∂ L ∂ W ( l ) \mathbf{W}^{(l)} \gets \mathbf{W}^{(l)} - \alpha \frac{\partial \mathcal L}{\partial \mathbf{W}^{(l)}} W ( l ) ← W ( l ) − α ∂ W ( l ) ∂ L b ( l ) ← b ( l ) − α ∂ L ∂ b ( l ) \mathbf{b}^{(l)} \gets \mathbf{b}^{(l)} - \alpha \frac{\partial \mathcal L}{\partial \mathbf{b}^{(l)}} b ( l ) ← b ( l ) − α ∂ b ( l ) ∂ L 特别注意,初始化边权时不能初始化为 O \mathbf{O} O
通常,初始化边权矩阵应该随机化,矩阵里的每个元素接近于 0 0 0 [ − ε , ε ] [-\varepsilon, \varepsilon] [ − ε , ε ]
梯度检验 在模型训练过程中,有时会出现这种情况:虽然学习曲线很正常,一直单调递减,但是训练结果不尽人意.这有可能是出现了难以察觉的 bug,让训练结果相比无 bug 的模型差出了一个量级.
一种排查 bug 的方式是 梯度检验 ,就是将反向传播算出的梯度与手动算出的近似值作对比,看看是否在数值上十分接近.
具体来说,保留每次迭代得到所有层的 ∂ L ∂ W ( l ) \frac{\partial \mathcal L}{\partial \mathbf{W}^{(l)}} ∂ W ( l ) ∂ L
Δ L = L ( W ( 1 ) , ⋯ , W ( l ) + E , ⋯ , W ( L ) ) − L ( W ( 1 ) , ⋯ , W ( l ) − E , ⋯ , W ( L ) ) ∥ ∂ L ∂ W ( l ) − Δ L 2 ∥ E ∥ ∥ ≈ 0 \begin{align*}\Delta \mathcal L = \mathcal L (\mathbf{W}^{(1)}, \cdots, \mathbf{W}^{(l)} + \mathbf{E}, \cdots, \mathbf{W}^{(L)}) - \mathcal L &(\mathbf{W}^{(1)}, \cdots, \mathbf{W}^{(l)} - \mathbf{E}, \cdots, \mathbf{W}^{(L)})\\ \left\|\frac{\partial \mathcal L}{\partial \mathbf{W}^{(l)}} - \frac{\Delta \mathcal L}{2\|\mathbf{E}\|}\right\| &\approx 0\end{align*} Δ L = L ( W ( 1 ) , ⋯ , W ( l ) + E , ⋯ , W ( L ) ) − L ∂ W ( l ) ∂ L − 2∥ E ∥ Δ L ( W ( 1 ) , ⋯ , W ( l ) − E , ⋯ , W ( L ) ) ≈ 0
其中任取 ∥ E ∥ = 10 − 4 \|\mathbf{E}\| = 10^{-4} ∥ E ∥ = 1 0 − 4 E \mathbf{E} E l − 1 l - 1 l − 1
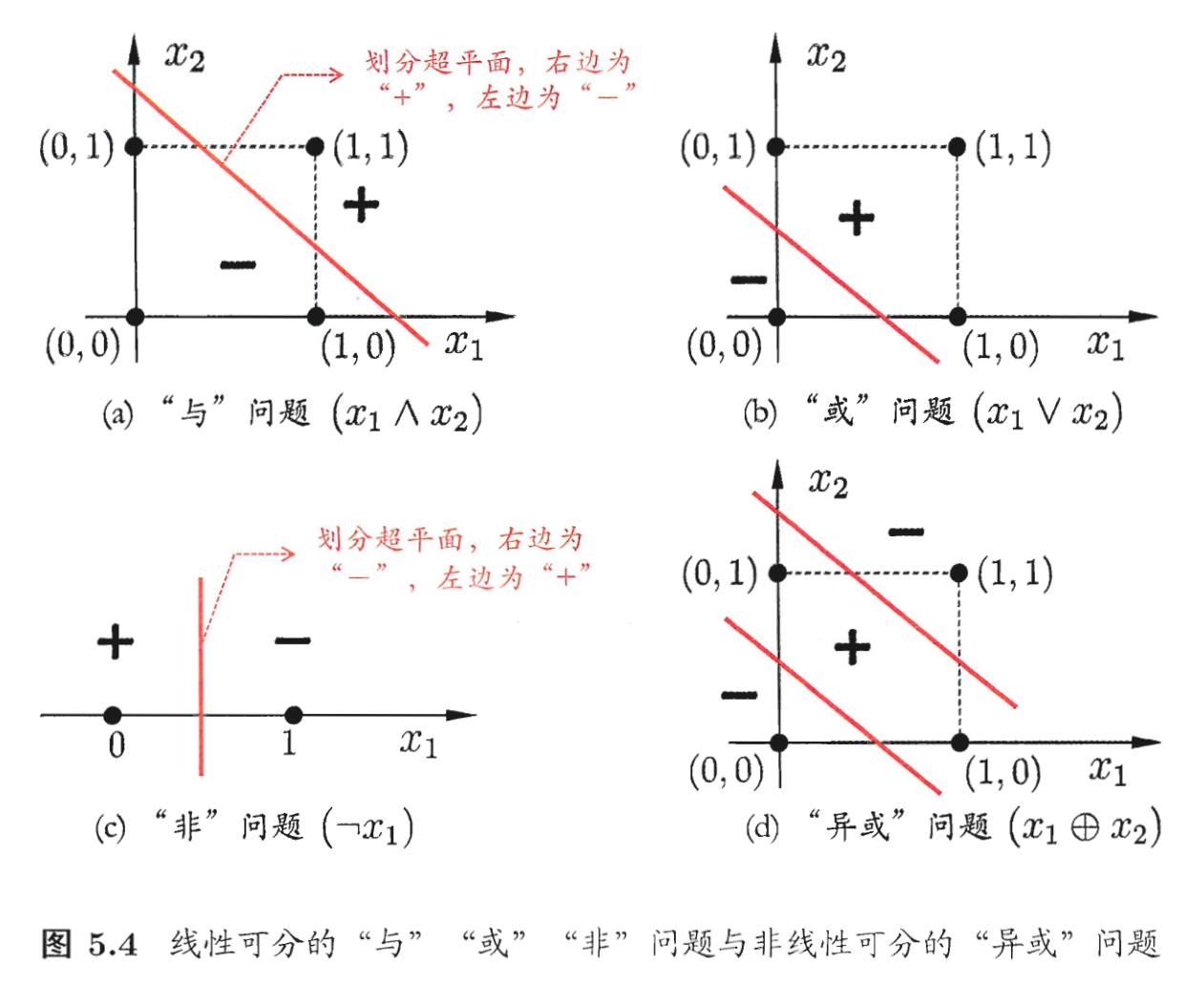 但对异或问题进行简单的二分类(对角的一组点归为一类)是无法将两种输出分开来的(线性不可分),因为你无法使用一条直线将这两类交叉的点群分开来.
但对异或问题进行简单的二分类(对角的一组点归为一类)是无法将两种输出分开来的(线性不可分),因为你无法使用一条直线将这两类交叉的点群分开来.